


Before we jump into the topic straight away, let’s have a look at the overview of this subject. Figure out where we find Artificial Intelligence (AI), Machine Learning(ML), Deep Learning and Data Science in the vast subject area of Computer Science(CS).
As you can see from the Euler Diagram, below, ML is a subfield of AI. Which itself is a subfield of CS, while Deep learning is a subfield of ML. Data science is a recent development that includes not only ML, AI and CS but also statistics, data storage and web application Development.
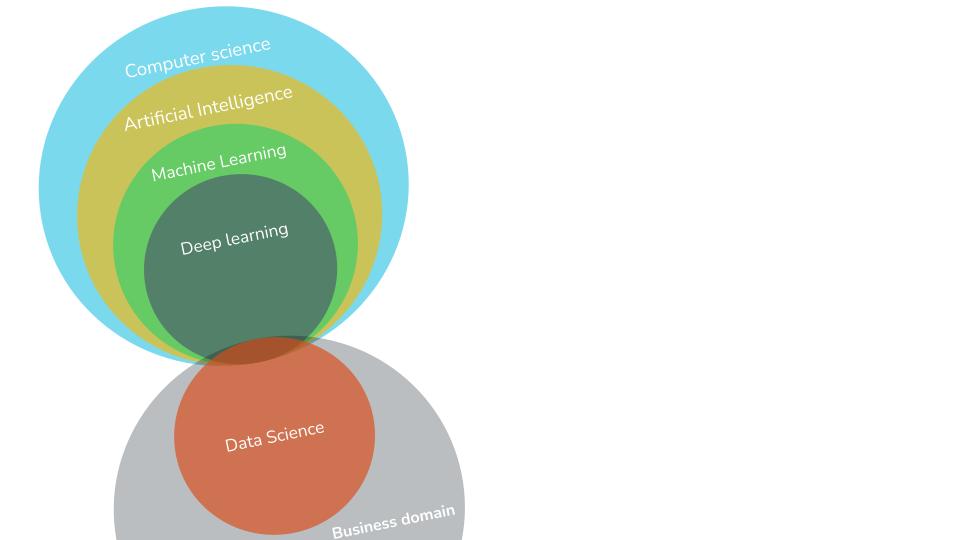
Let’s take a quick look at what each of these terms simply means, except CS, since it is a broader topic and far from where we focus on this blog.
What is Artificial Intelligence or AI?
Well, there is no concrete definition for this term. “Cool things that a computer can do” is also a valid definition from the perspective of gaming application developers. Here are some applications of AI so that you can have your own idea about AI.
- Self-driven cars
- Image and video processing
- Content recommendation
According to my understanding, if the computer can take a decision of its own after evaluating certain dimensions of the problem to be solved. This system must use an algorithm to select its decision from all the possible solutions from its training. Such a system can be considered as AI.
When we apply an AI system to a device and get the respective work done physically, it can be called a robot, even though it is not necessary to be in a human shape as we see in science fiction.
What is Deep Learning?
We already know that Deep Learning is a subfield of ML. Depth of deep learning refers to the complexity of the mathematical models which researchers have to develop to solve a certain problem. When you get into the process of solving a problem with the aid of ML, the deep you go into the problem, the complexity of the model will also increase. But it allows them to find effective, accurate solutions not only quantitatively but also qualitatively.
This method enables researchers to dive deep into the topic or acquire further knowledge on the topic over time.
What is Data Science?
Data Science is a recent development, and it covers several disciplines from Computer science to statistics, including different algorithms, Scientific methods and processes. AI and ML benefit from data science intensively, since this is the science of extracting useful information from a large feed of noisy data, which means not very clean. So that ML algorithms can be optimized to train themselves according to the options and solutions available in data science.
What is Machine Learning?
ML is used to produce an algorithm that can learn patterns in a data set and use that knowledge to perform a specific task.
It is important to have an idea about ML concepts before we dig into ML techniques.
- Features – Attributes that describe instances of a data set, can be easily collected in a spreadsheet, for example.
- If it’s an online store, a number of purchases, products bought, age of the customer etc…
- Feature selection and Engineering – You will have to select the most relevant or the optimal features according to your requirement to include them in the training phase. Even from those selected features, you will have to eliminate or adjust those features on the training process and this is called feature engineering.
- Data set – also called raw material for the ML. Usually, this is historical data. So that you can use it to detect patterns and design algorithms. The data set is composed of individual data properties, and it is ready for analysis.
- Learning, training – It’s the process of selecting patterns within the dataset. Once patterns are identified, predictions can be done by feeding new data to the system. For example.
- If it’s an online book store, a pattern of a customer identified for the Book titles searched and purchased, it’s easy to suggest to him new books that he is likely to buy again. Or a new customer who adopts the same patterns.
- Tuning – Optimizing the patterns of an algorithm to find the best combination for your specific data set. Finding optimal parameters for tuning by using automated methods is called hyperparameter optimization.
- Models – After training the system, we get a model to make predictions with the new data by comparing the patterns already learned from training data or historical data.
- Validation – To check how well the system performs the given task. It is important to find the best performing metric with respect to the given tasks. The data set is divided into two parts in the ML process.
- Training data – to train the model
- Testing data – to validate the model
How to categorize ML?
In the above diagram, you can see the structure of ML. As you can see, there are four main types of techniques, note that in some reading materials, Semi-supervised learning is referred to as Deep Learning. Each of the above types is further divided into 2 subcategories. Under those subcategories, there are respective ML techniques. Note that there can be different subcategories in some other reading material according to the point of view of the author, since there are no hard and fast rules or sharp separation between these techniques and new types of techniques are introduced frequently. Under those subcategories, the respective example ML algorithms are listed. Note that there are many other algorithms as well.
The scope of this blog is to give you a clear and general idea about the structure of ML and a basic understanding of the techniques. So there will be no digging deep into the techniques, but there will be links that you can use to read further if you are interested in a specific technique.
Let’s take a look at Types of ML techniques one by one.
What is Supervised Learning?
Its name suggests there is a supervisor in supervised learning. We train the machine using training data that is labelled. This means the data is already tagged correctly. After that, the new data set is provided to the machine. Then the supervised learning algorithm will analyse the training data and produces the correct labels for the new data set.
Supervised learning is categorised in to two categories of algorithms
- Regression – A regression problem is when the output variable is a real value. For an example, “weight”
- Classification – A classification problem is when the output variable is a category such as “Red” or “Green”
What are the algorithms belonged to Regression Category?
- Linear regression – The model finds the best fit line (the linear relationship) among the independent and dependent variables. There are two types:
- Simple Linear Regression – only one independent variable is present
- Multiple Linear Regression – more than one independent variable for the model to find the relationship.
Read Further about Linear regression from this link
- K – Nearest Neighbour- The algorithm assumes the similarity between the new data and available data and put the new data into the category that is most similar to the available categories.
Read Further about K – Nearest Neighbour from this link
- Random Forest – It contains a number of decision trees on various subsets of the dataset and takes the average of the results of all decision trees. Instead of relying on one decision tree, based on the majority votes of predictions, it predicts the final output.
Read Further about Random Forest from this link
What algorithms belong to Classification Category?
- Naive Bayes – It is a classification technique based on Bayes’ Theorem. A naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
Read Further about Naive Bayes from this link
- Decision Tree – There are two nodes, Decision Node and Leaf Node. Decision nodes are used to make any decision and have multiple branches, whereas Leaf nodes are the output of those decisions, and they can’t have any further branches. Nodes represent the features of a dataset, branches represent the decision rules, and each leaf node represents the outcome.
Read Further about Decision Tree from this link
- Neural Network – Set of algorithms, designed similarly to the human brain. Those are designed to recognize patterns. It can do labelling or clustering and classify data input. These algorithms can recognize numerical patterns, patterns contained in vectors. Etc…
Read Further about Decision Tree from this link
What is Unsupervised Learning?
If the training of the machine is carried out without classified data or labelled data and allow the algorithm to act on the information without guidance. The task of the machine learning algorithm is to sort the data according to patterns, similarities and differences. As the name suggests, no supervise provided to the machine, therefore the machine is restricted to find out the structure of data set by itself.
For example, think about feeding a picture with different animals without naming them as training data. The ML algorithm will recognize differences between animals in the picture and will keep them documented in its own way. So when another picture with animals is provided as the testing data, the ML algorithm should recognize similar animals from the previous training data in the new picture.
Unsupervised learning algorithms are categorized into two types.
- Clustering – A clustering problem is where you want to find the inherent groups within the data set
- Dimensionality reduction – A Dimensionality reduction Problem is where you have to reduce the number of input variables in data.
What algorithms belong to Clustering Category?
- K – Means – the objective of K-means is to group similar data points together and discover underlying patterns. K-means looks for a fixed number (k) of clusters in a dataset. You’ll define the number k, which means the number of centroids (the imaginary or real location representing the centre of the cluster) you need in the dataset. Then allocates every data point to the nearest cluster, while keeping the centroids as small as possible.
Read Further about Decision Tree from this link
- Neural Networks – As described above, It can do labelling or clustering and classify data input.
- Hidden Markov – Many internal states are hard to determine or observe. An alternative is to determine them from observable external factors. You can use Hidden Markov model to do that.
Read Further about Hidden Markov from this link
What algorithms belong to dimensionality reduction Category?
- Principal Component Analysis – It‘s a statistical procedure that uses an orthogonal transformation that converts a set of correlated variables to a set of uncorrelated variables. It is the most widely used tool in exploratory data analysis and in machine learning for predictive models.
Read Further about Principal Component Analysis from this link
What is Semi-Supervised Learning?
Semi-Supervised learning is a combination of supervised and unsupervised learning techniques. In semi-supervised learning, the algorithm learns from a data set that includes both labelled and unlabelled data, mostly unlabelled data. This technique is important because when you do not have enough information or not possible to label the data correctly because somehow you will have to increase the amount of training data to train it correctly. In such times, you can use Semi-Supervised Learning techniques.
For example, think about developing a fraud detection system by training an ML algorithm. You already have some information about persons who are frauds. But you don’t exactly know who else are frauds from the list. In this case, you can label already detected frauds in the training dataset and let others be without labelling. The semi-supervised ML algorithm will check for patterns of frauds within the data set and after analysing others, it will identify the frauds whom you couldn’t identify before.
Semi-Supervised Learning algorithms can also be subdivided very specifically into
- Clustering
- Classification
But generally, those algorithms are referred to as Semi-Supervised Algorithms
What are the Semi-Supervised Algorithms?
- Heuristic approach – It is a technique designed for solving a problem more quickly when classic methods are too slow, or for finding an approximate solution when classic methods fail to find any exact solution.
Read further about Heuristic algorithms from this link
- Cluster assumption – It means that if points are in the same cluster, they are likely to be of the same class. There may be multiple clusters forming a single class.
- Continuity assumption – algorithm assumes that the points which are closer to each other are more likely to have the same output label.
- Manifold Assumption – The data lie approximately on a manifold of a much lower dimension than the input space. This assumption allows the use of distances and densities which are defined on a manifold.
Read further about 3 types of algorithms from this link
What is Reinforcement Learning?
The training of ML algorithms to make a sequence of decisions is called Reinforcement Learning. The aim is to train the algorithm to achieve a goal in an uncertain, potentially complex situation. The machine can make trial and error decisions. For each successful decision it will gain a reward and for every error there will be a cost. The aim of the ML algorithm is to maximize the total rewards. It is totally up to the model or the algorithm to decide how to increase the total rewards, without the involvement of the programmer.
Training an algorithm to drive an autonomous car is one of the best examples of reinforcement learning algorithms. There are so many aspects to consider when driving a car, such as speed, stability, comfort of the passengers, safety of the car, laws to be obeyed on the road, decide what is important whether it is the time to destination, or the comfort of the passenger or the fuel economy etc… For each of the above points, reward and pay system be
Reinforcement Learning algorithm types are also further divided into
- Control
- Classification
According to the point of view of the application, But generally those algorithms are referred to as Reinforcement Learning Algorithms.
What are the semi Supervised Algorithms?
- Q- Learning – It doesn’t require a model of the environment (model-free), Q-learning algorithm finds optimal way in the sense of maximizing the total reward value over any other ways, “Q” refers to the function that the algorithm computes
Read further about Q- Learning from this link
- Sarsa – State–action–reward–state–action is an algorithm for learning a Markov decision process. The name suggests that the main function for updating the Q-value depends on the current state of the agent “S”, the action the agent chooses “A”, the reward “R” the agent gets for choosing this action.
Read further about Sarsa from this link
Conclusion
There are many ML algorithms available other than the ones that I have mentioned here in this blog. You can decide on one according to your requirement and the possibility of training techniques. ML Techniques allows you to create an AI system and implement it on the respective task that you want to get done. So that it will surely save your time, money and overall it will make your life easy.
This article was developed during collaboration with Manoj Rasika Koongahawatte, during Predictea Analytics Programme.