


What was this project about?
The aim of this project is to find out the strengths and weaknesses of the competitor’s product by analysing the reviews of the customers. Both positive and negative for this desk lamp.
On Amazon, the customer can write a review regarding the respective product and also can give a star rating from 1 to 5.
From this information, I collected good reviews with a rating of 4 stars and above. Generally, those reviews are positive and contain the strengths of the product. Then, I collected the reviews with the rating of 1 star, which tells about weaknesses of the competitor’s product.
I want to avoid weaknesses while developing a new product and make strength used for marketing and promotion.
In the end, the analysis was presented to the client. So that, at a glance, our client can get some insights to improve the design of their table lamp which they are going to introduce to the market.
After analysing a product, here are the things customers value the most: brightness level adjustability, quality, price, simplicity, design, USB connectivity, power adapter function.
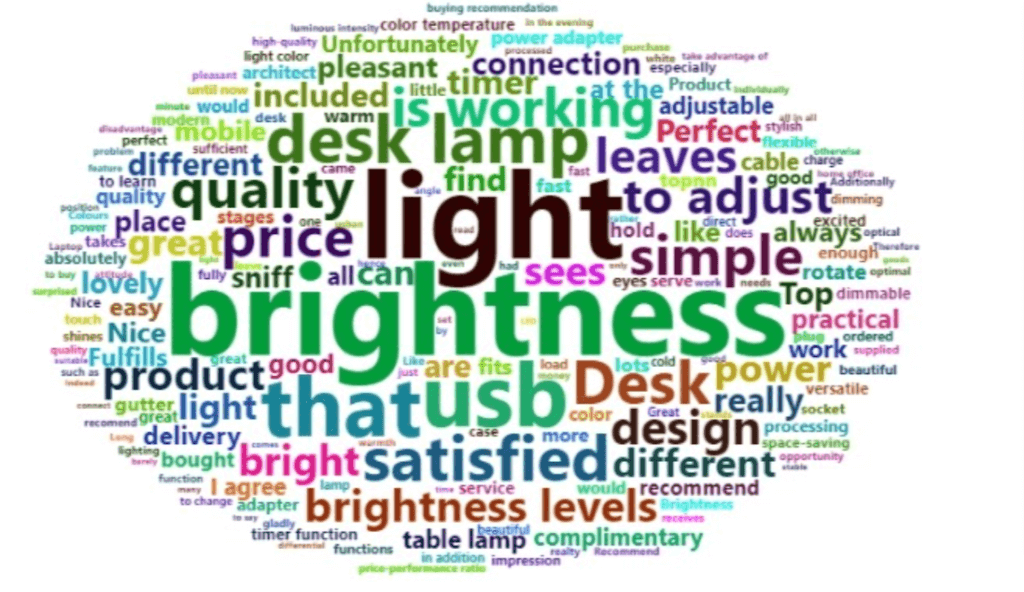
And the things customers expect to improve: power adapter issues, light bulb position, lampshade, poor material quality.

How, exactly, this analysis has been done, is explained in the part underneath.
Creating Word Clouds
This task consists of two parts,
- Web scrap the review text
- Web scrap 5star rated reviews
- Web scrap 4star rated reviews
- Create an array of review text for the positive reviews’ word cloud
- Web scrap 1star rated reviews
- Create an array of review text for the negative reviews’ word cloud
- Creating positive and negative word clouds by feeding the data to the R code respectively.
From the product page, navigate to “customer reviews” part and selected the 5star ratings.
Check the URL to understand how it changes when you go to the next page of the 5-star reviews. Check how many reviews are there on a page. Then check the total number of reviews so that you can calculate how many pages will be there. In my case, there were 10 reviews per page and totally there were 505 reviews. That means 51 pages.
With this information, you can create a character vector of URLs for each page. Then find the HTML element for the content part and create a character vector with that as well. Then feed both vectors into mapply function as shown in the following code block:
# Importing Libraries
library(rvest)
library(dplyr)
# 5star reviews
five_star_links<- c(paste0("https://www.amazon.de/-/en/product-reviews/B0897Q7GJ2/ref=cm_cr_arp_d_paging_btm_next_3?ie=UTF8&filterByStar=five_star&reviewerType=all_reviews&pageNumber=", 1:51))
five_star_css <- c(rep(".review-text-content",51))
five_star_txt <- mapply(function(five_star_links, five_star_css) five_star_links %>% read_html() %>% html_elements(five_star_css) %>% html_text(), five_star_links, five_star_css)
# Do the same to the 4 star reviews and create an array which includes both 4 and 5 star reviews as shown in the following part of the code.
# good reviews array
good_reviews <- c(five_star_txt,four_star_txt)
good_reviews <- as.array(good_reviews)Follow the same procedure to extract 1star reviews and assign them to a variable which you can name as “bad_reviews”.
Creating word cloud
Following libraries were imported to create the word cloud and clean the text which is about to be fed into the word cloud.
library(translateR)
library(wordcloud)
library(RColorBrewer)
library(wordcloud2)
library(tidytext)
library(tm)Then you can start the part where you start to create the word cloud. If you want to create the “good_reviews” word cloud first, feed that object to the following code to start cleaning data. Here you will remove the numbers and punctuation and spaces from the text.
docs <- Corpus(VectorSource(good_reviews))
docs <- docs %>%
tm_map(removeNumbers) %>%
tm_map(removePunctuation) %>%
tm_map(stripWhitespace)Then use the following part of the code to convert all text into lowercase, remove words in the English language which is generally do not mean full, such as “is” and “that”. Also, you can fine-tune your word cloud words by removing other words which, you think, are not useful to the decision-making process. You will notice that in this example, I had to clean both English and German words since reviews were in both languages.
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeWords, stopwords("german"))
docs <- tm_map(docs, removeWords, stopwords("english"))
docs <- tm_map(docs, removeWords, c("lampe"))
docs <- tm_map(docs, removeWords, c("super"))
docs <- tm_map(docs, removeWords, c("gut"))
docs <- tm_map(docs, removeWords, c("lamp"))Note that in Amazon reviews, you have only the following options
- Select reviews either originally written in English or German language. Then it will show you the top or recent reviews for the respective language. But you can’t choose the star ratings language-wise.
- Select reviews according to the star ratings, then you will get both English and German reviews, but can’t separate according to the language. So that both English and German words will appear in the word cloud.
- You can translate all reviews to either English or German or any other language and see them according to the star rating and other filters, but only the originally reviewed language is possible to web scrap without a problem.
- Or you can web scrape all the words and in the final stage of the process translate the data frame of the word cloud into English or any other language you prefer using any translation method Within the code or outside the code. Then feed it again to the word cloud function.
Then you can do the pattern cleaning using the following block of code.
# cleaning text using pattern search
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, "", x))
# docs <- tm_map(docs, toSpace, " " )
docs <- tm_map(docs, toSpace, "\n" )
docs <- tm_map(docs, toSpace, "\n\n\n\n\n\n\n\n\n\n" )
docs <- tm_map(docs, toSpace, "nnnnnnnnnn" )After you are done with all the cleaning of your extracted text, convert it to a matrix, and thereafter a data frame as shown below.
# assigning cleaned text to a metric and thereafter a data frame
dtm <- TermDocumentMatrix(docs)
matrix <- as.matrix(dtm)
words <- sort(rowSums(matrix),decreasing=TRUE)
df <- data.frame(word = names(words),freq=words)You can see the most used words with the following function.
# the number can be changed as per your wish to see how many words.
Top_words <- head(df,50)Finally, create the Word cloud and adjust the graphics and design of it by changing values in the following block of code.
wordcloud2(data=df, size=0.5, color='random-dark', backgroundColor = "white", minRotation = 0, maxRotation = pi/2,rotateRatio = 0, shape = "circle",widgetsize =c("900","900"))If you have successfully followed the steps above, you will get nice word clouds as shown at the beginning of this blog.
In case you need to get the word cloud for “bad_reviews” it is just a matter of changing the vector source into “bad_reviews” in the beginning of the word cloud code blog above.
Conclusion
You can easily understand how good or bad some features are in the product according to the size of the respective word which you see on the word cloud. A particular word is bigger when it was mentioned in the reviews more time than other words which are smaller to its size.
Finally, you can understand which features you have to keep as it is, to be improved and which features to be removed when designing the new product and get the advantage in the market over other similar products.