


I was wondering what makes a nice Christmas Song, and If I can build a supervised machine learning model that can make accurate predictions on whether a song is likely to be popular or not.
So this project includes the following major steps
- Search for playlists with popular Christmas songs and import the metadata with Spotify in Python
- Build a supervised machine learning that predict the popularity based on several features contained in the metadata
- Try different algorithms and evaluate the model and plot the feature importance
I’ll walk you through step by step and also let you know the difficulties, I faced and how I solved them.
Creating Spotify credentials
The first prerequisite is to have a Spotify subscription. Go to the developer page of Spotify, where you can connect your account to developer account.
Once you are done, you go to your “Dashboard” and “Create new App”. After that, you can access your CLIENT ID and your CLIENT SECRECT. I was facing a client authentication issue and this was solved by going to “Edit settings” and put as “Redirect URI” the following: https://my.home-assistant.io/redirect/oauth.
Now we swap to the notebook, and you can see the necessary import statement in Python for this project.

We can connect to the client with our credentials (CLIENT ID, CLIENT SECRECT).

Just fill the red lines with your specific data, use them properly, as they are confidential.
Building a model after downloading tracks from Spotify
That done, we define two functions that download the tracks of a given playlist and preprocess the metadata for us, so we can start to build a model on it.

Now, a pandas data frame with the data of one specific playlist is formed by calling consequentially the two functions.
The username and the playlist_id can be found from your Spotify account. For the first one, click on the user that has built the playlist. On the profile click on “…” and “Copy link to profile” For the second one, click on “…” and go to “Share” and “Copy link to the playlist”
When you paste the link, you get a URI like this. In both cases, the part between the “/“ and the “?” is of interest for you and must be given as an argument for the get_user_playlist() function.
This can be done for several playlist and the data is merged into one panda dataframe. Then the features and label for your model are specified.
Spotify feature vector – metrics that can be used from Spotify
In my case, the input feature vector comprised all the following columns:
- duration
- danceability
- loudness
- tempo
- acousticness
- energy
- valence
- liveness
- speechiness
For the label I want my model to predict, I used the column “popularity”. So built a supervised regression model that based on the input features predicts the popularity of it. I built a pipeline that takes care of the scaling of the features and the building of the model. I tried different regression algorithms. Furthermore, I chose a gradient booster as it performed the best. The model was evaluated by the r^2 score. As the model showed already a very high score, the hyperparameter was omitted this time.

Christmas song features
Finally, I had a look to the feature importance and plotted them. This gives you the chance to learn something about the underlying mechanisms the model is built on.
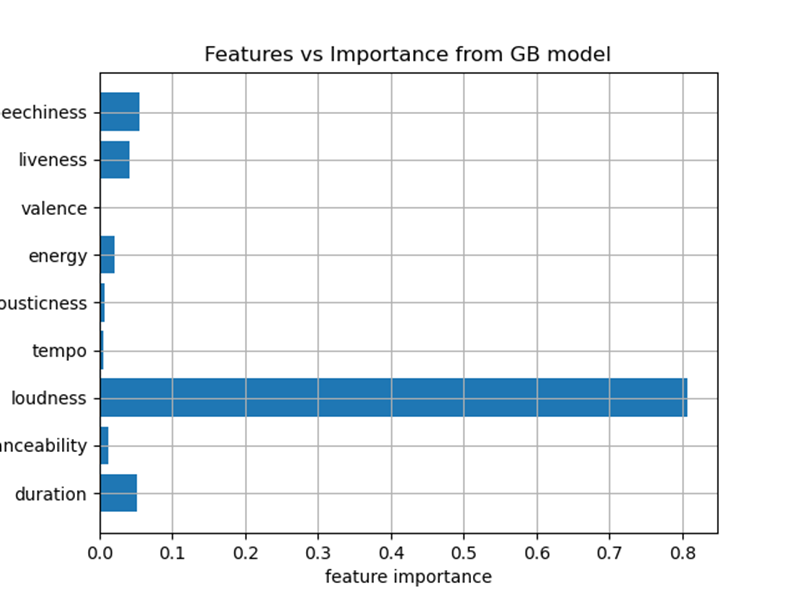
Conclusion
It is possible to build an accurate model based on the metadata from Spotify as features to forecast the popularity of Christmas songs. Maybe you have a similar idea in mind, give it a shot!